在多模态模型里,CLIP-style encoder 往往把视觉表征过早地拉近到文本空间:对于抽象层面的问答,如总结图片大致内容,这样的表征其实是没有什么问题的,但一旦追问与语言无强依赖的细节,模型就更易出现幻觉。根本原因之一,是在文本空间对齐之前,原生视觉结构已被不可逆地压缩 / 丢失,而语言模型不得不「二次解码」来自他模态的 embedding,导致对齐脆弱、推理链条变长。
为此,北大、UC San Diego 和 BeingBeyond 联合提出一种新的方法——Being-VL 的视觉 BPE 路线。Being-VL 的出发点是把这一步后置:先在纯自监督、无 language condition 的设定下,把图像离散化并「分词」,再与文本在同一词表、同一序列中由同一 Transformer 统一建模,从源头缩短跨模态链路并保留视觉结构先验。
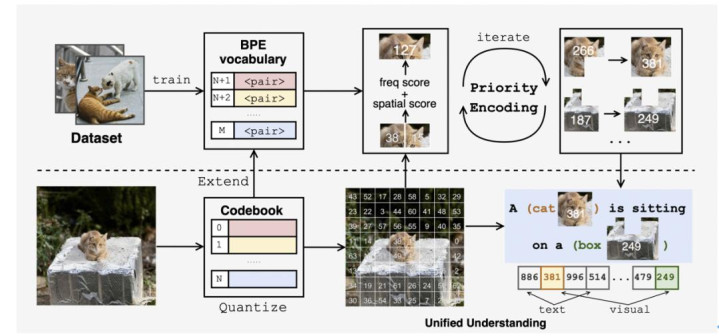
Being-VL 的实现分为三步。首先用 VQ(如 VQ-GAN)把图像量化为离散 VQ tokens;随后训练一个视觉版 BPE,不只看共现频次,还显式度量空间一致性,以优先合并那些既常见又在不同图像中相对位置稳定的 token 对,得到更具语义与结构的 BPE tokens;最后把视觉 tokens 与文本 tokens 串成同一序列,进入同一个自回归 LLM 统一建模,不再依赖额外 projector 或 CLIP 对齐。整个 BPE 词表学习仅依赖图像统计,不看文本,真正把「语言对齐」留到后续阶段。

论文链接:https://arxiv.org/abs/2506.23639
项目主页:
https://beingbeyond.github.io/Being-VL-0.5
GitHub:
https://github.com/beingbeyond/Being-VL-0.5
与「把视觉直接投到文本空间」有何本质不同?
传统做法让 LLM 去再解释外部视觉 encoder 的连续 embedding;即便 encoder 学到了丰富模式,没有对应解码器,LLM 也要额外学习如何「读懂」其他模态,这会放大模态鸿沟并诱发幻觉。Being-VL 把视觉提前离散化为可组合的 tokens,并在序列里与文本统一建模,减少表征形态错位,缩短跨模态因果链条,从而在保持感知细节与高层语义的同时,降低「想象成分」。
针对视觉场景设计的 BPE tokenizer:频次 × 空间一致性
文本大模型中的 BPE 只看「谁和谁经常相邻」。在视觉里,如果只按频次去合并,容易破坏结构。Being-VL 因此提出 Priority-Guided Encoding:基于 score P (a,b)=F (a,b)+α・S (a,b) 进行 BPE 词表构建,其中 F 为邻接频次,S 衡量在不同图像中的相对位置一致性,相似度用高斯核对齐。这样得到的视觉词表既覆盖高频模式,又保留空间结构。并且这个过程完全不依赖文本。
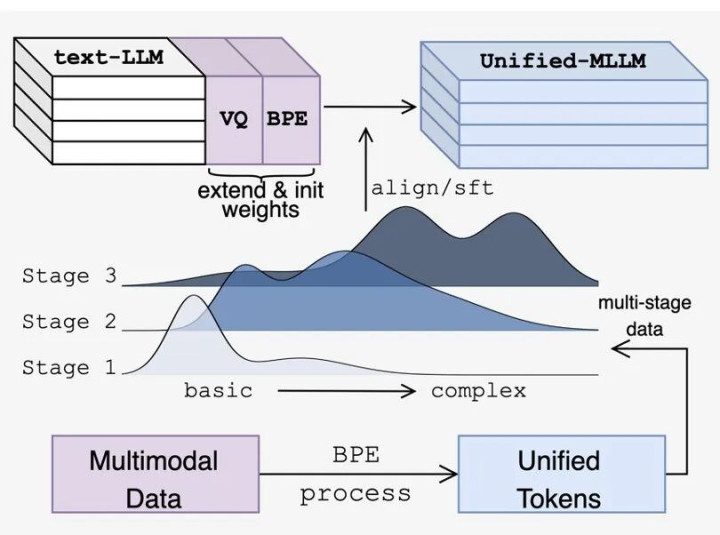
三阶段训练:从 VQ/BPE embeddings 到 LLM backbone 的渐进解冻
为了让统一的离散表示平滑接入语言模型,Being-VL 采用三阶段(3-stage)训练并显式控制解冻顺序:
Stage-1 / Embedding Alignment:只训练新扩展的视觉 token embeddings(包括 VQ 与 BPE 两部分),其余参数全部冻结,完成基础对齐而不扰动原有语言能力。
Stage-2 / Selective Fine-tuning:解冻 LLM 前若干层(默认约 25%),其余层继续冻结,让跨模态交互首先在底层表征中发生。
Stage-3 / Full Fine-tuning:全量解冻,在更复杂的 reasoning /instruction 数据上收尾,强化高级能力。
与解冻节奏配套,数据采用 curriculum:从基础 caption 与属性识别,逐步过渡到视觉问答与多轮指令,显式对齐 BPE 的「由局部到整体」的层级特性。消融表明:渐进解冻 + curriculum 明显优于单阶段训练;只用其中任一也不如两者合用。
实验与分析
Being-VL 的一系列对照实验给出一个清晰结论:把图像先离散化并做视觉 BPE,再与文本在同一序列里统一建模,既稳又有效。相较传统「先拉到文本空间」的做法,这种统一的离散表示更少丢失原生视觉信息,因而在细节敏感的问答与抗幻觉上更可靠;而一旦移除 BPE,性能与稳健性都会整体下降,说明增益主要来自于把「常见且空间关系稳定」 的视觉模式合成更有语义的 tokens,让 LLM 在更合适的粒度上推理。
训练与规模选择方面也有明确「可执行」的答案。三阶段渐进解冻 + curriculum 是默认策略:先只对齐 VQ/BPE embeddings,再解冻一部分 LLM backbone,最后全量微调,能在不扰动语言能力的前提下稳步提升跨模态理解。
Visual BPE Token 激活机制可视化
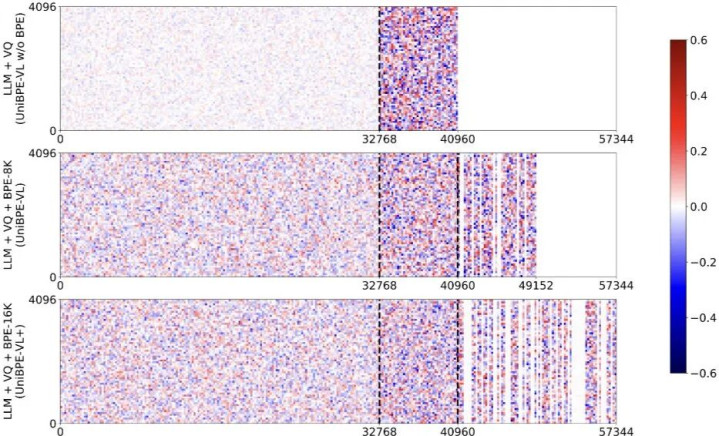
Embedding 权重的可视化揭示了词表设计对跨模态表征的影响:在不使用 visual BPE 的基线模型(上图)中,文本与视觉 token 的权重呈现显著偏置与分离,体现出明显的模态隔阂;而引入不同词表大小的 visual BPE(中、下图)后,两类 token 的权重分布趋于均衡与同构,说明 BPE 在更细粒度上对齐了子词 / 子片段层面的统计与表征空间。由此带来的直接效应是跨模态注意力的共享基准更一致、梯度信号更可比,从而降低模态间的分布漂移与共现偏差。
词表大小对训练效率与扩展潜力的影响
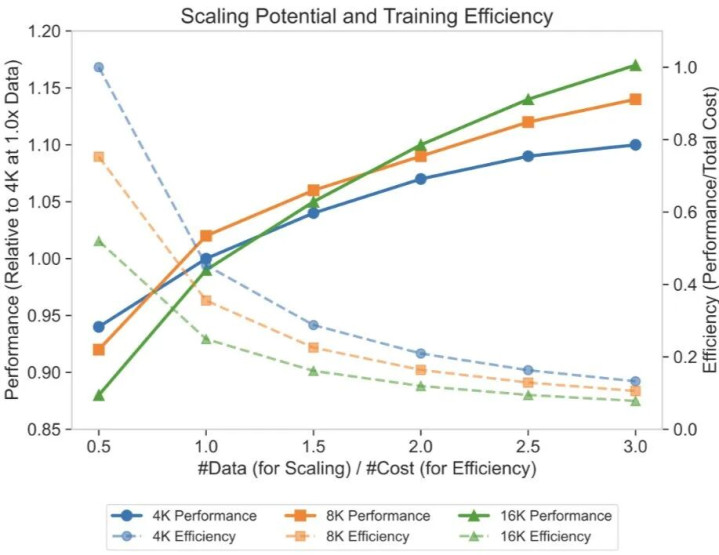
研究进一步考察了 BPE 词表规模的作用。可视化结果显示:在训练资源受限的情形下,与 VQ 等规模的码本在表达能力与训练效率之间取得了更佳平衡,处于「甜点区」。当词表继续增大(≥16K)时,会出现大量低利用率、呈稀疏分布的 token,导致单位算力的收益下降。不过,这也预示着在数据规模扩张时存在更强的上限潜力。论文提出的方法可在更大的词表与更多数据的配合下,释放这部分扩展空间,进一步提升模型表现。
发展与小结(Being-VL-0 → Being-VL-0.5)
Being-VL-0 (ICLR 2025)
Being-VL-0 给出的是视觉离散化 + BPE 的可行性与动机:从理论分析与 toy 实验出发,得出结论 BPE-style 合并能把必要的结构先验灌注进 token,使 Transformer 更易学习;并初步探索了两阶段训练(PT→SFT)、文本 embedding 冻结策略与数据 scaling 带来的稳健增益。
项目地址:
https://github.com/BeingBeyond/Being-VL-0
Being-VL-0.5 (ICCV 2025 highlight)
Being-VL-0.5 则把这一路线进一步优化为一个统一建模框架:频次与空间一致性联合的 Priority-Guided Encoding、VQ/BPE/LLM 三阶段渐进解冻、以及配套的 curriculum 数据策略。
能加杠杆的炒股软件.配资炒股之家.线上股票配资炒股门户网址提示:文章来自网络,不代表本站观点。